
Eight equity analysts look at the same company. Three say buy the shares, three say hold, two say sell. Target prices range 50% apart. That divergence is not a bug. It is the market working as intended.
In previous volumes, we talked about AI reshaping the analyst workflow and changing skillsets, unpacked the hallucination problem, and made the case for purpose-built workflow solutions. But there is a deeper question we have not yet addressed:
“What happens when AI agents in the market form the same opinion? Can they?”
Why Analysts Disagree (And Why That Matters)
An analyst’s mind does not work like a data processor. Investment decision-making is a complex process built on opinions formed by looking at data, deriving insights, layering prior experience, and imposing judgment filters that are inherently personal. Two analysts can look at the same earnings transcript and arrive at completely opposite conclusions, and both can be right, depending on their thesis, their time horizon, and their risk appetite.
This is exactly why target prices for the same company differ by 50% across analyst reports. This divergence creates the spread between buyers and sellers. It creates the opportunity to invest.
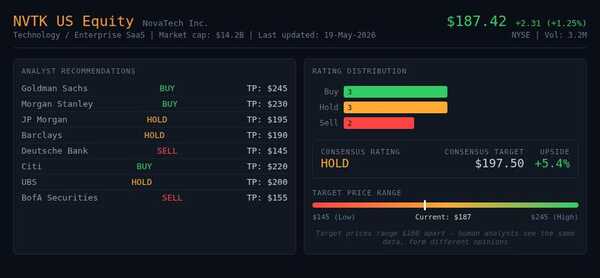
What Happens When AI Analyses the Same Information?
Most information that drives equity research is publicly available. Earnings transcripts, SEC filings, annual reports, investor presentations, competitor data. Information scraping is not a big deal for AI. The question is what happens after the scraping.
So if every AI agent has access to the same publicly available information and processes it using fundamentally similar underlying models, will the opinions these agents form also be the same? My answer is yes, to a large extent.
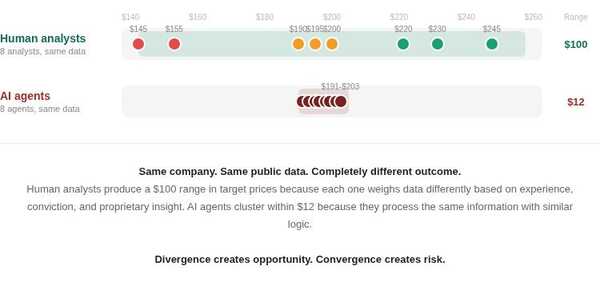
AI Chases the Narrative, Not the Fundamentals
There is another dimension to this problem. AI models do not just process structured financial data. They are heavily influenced by the volume and sentiment of information circulating in the market at any given time.
When the Strait of Hormuz situation escalated and there was talk of potential shutdowns, panic buying started in induction-based electrical appliances. The narrative was everywhere on the internet: gas supply disruptions, cooking alternatives, induction demand surge. AI models picking up this sentiment would naturally conclude that induction appliance companies were about to see a demand spike.
The problem? The AI was chasing the headline, not the fundamentals. A seasoned analyst would have immediately asked the questions that AI did not: what percentage of this company’s revenue actually comes from induction products? What is their inventory position? Can they even scale production quickly enough to meet a sudden demand surge? What happens when the panic subsides?
An experienced analyst with domain knowledge would have seen through this in minutes. The AI, processing the same internet-wide information as every other AI agent, simply amplified the panic.
This is the fundamental difference between human judgment and AI analysis. An analyst applies a logical framework, while AI, especially when running on publicly available data, applies pattern matching at scale. And when multiple AI agents apply the same pattern matching to the same information, they converge.

Hypothetical Possibility of the Simultaneous Sell-Off?: A First-of-Its-Kind Risk
Imagine a stock market run by AI agents, and imagine a large-cap company reports a quarter that misses estimates. Every AI agent processes the same earnings miss, the same transcript language. They all reach a similar conclusion: downgrade.
Large-cap companies are particularly vulnerable information, which means AI opinions on them are most likely to converge. The very completeness of their public data works against them.
Layer in algo trading agents that execute automatically at machine speed, and you get a cascading effect. The initial sell triggers further AI analysis, which confirms the sell thesis, the stock is falling so it reinforces the sell signals, which triggers more selling. The feedback loop is instantaneous.

The Solution: Your Data, Your Infrastructure, Your Opinions
What breaks this convergence? What gives your firm an edge when every AI agent in the market is reading the same public data and reaching the same conclusions?
Proprietary information. Data that is not available to every AI agent on the internet. For this, organisations need to take stern steps to stop analysts from using generalist LLM models to upload their data. Do not upload your data to someone else’s AI agent. Build your own.
Your firm has years of proprietary research notes, internal models with unique assumptions, records of management meetings, channel checks, sector-specific databases, and accumulated institutional knowledge. This is your competitive advantage. And it only works as an advantage if your AI agent has exclusive access to it.
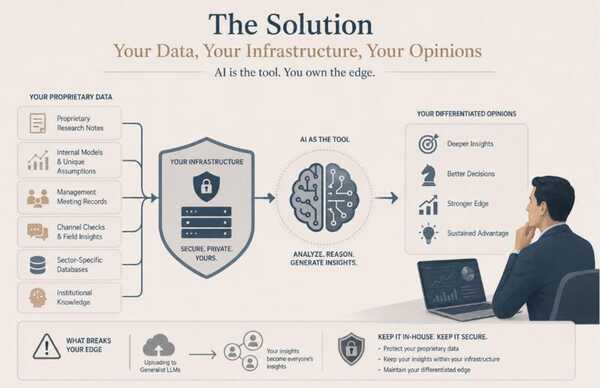
For decision makers: it is more important than ever to store your proprietary data securely on your own AWS or cloud infrastructure and build AI workflow solutions that leverage that data without exposing it to third-party models. This is not paranoia. This is competitive strategy.
The firms that do this will have AI that forms differentiated opinions. The firms that rely on public LLMs and public data will find their AI telling them exactly what everyone else’s AI is already saying.
(This is exactly what we are building at FootNote. We help organisations build custom AI workflow solutions where all data remains within your infrastructure. Your proprietary research, your models, your competitive edge, never leaves your control.)
The Bottom Line
The diversity of human opinion is what makes markets work. AI, left unchecked and running on the same public data, will erode that diversity. It will chase narratives instead of fundamentals. Opinions will converge. And when they converge at machine speed, the consequences could be severe.
The future is not AI replacing analyst judgment. It is AI amplifying the unique perspective that each firm brings to the table. But that only works if the AI has access to something unique. Build your own data moat. Keep your proprietary information within your walls. And make sure your AI works for you, not alongside every other AI in the market.
(After all, not everyone has the same taste in music as you do, so why follow the herd)

What Is Your Take?
I have been thinking about this problem for a while now, and I genuinely believe opinion convergence is one of the most underappreciated risks in AI-driven research today.
Have you seen AI tools chasing narratives and ignoring fundamentals in your own workflow? If you are a decision maker, have you started thinking about how to differentiate your firm’s AI capabilities from the rest of the market?
I would love to hear your perspective, the wins and the frustrations.
This post is published by CA Siddhartha Dongre, founder of SP2 Analytics and FootNote.AI.
SP2 Analytics provides qualified offshore research analysts (CAs, CFAs, MBA Finance) to investment banks, PE firms, VC funds, equity research shops, and consulting companies worldwide. www.sp2analytics.com
FootNote builds custom AI solutions for investment research workflows. www.aifootnote.com
If you are exploring either side of the equation — whether you need skilled analysts or want to build AI workflow tools for your team — let us talk.
Email: sid.dongre@sp2analytics.com | WhatsApp: +91 8983333940 | LinkedIn: CA Siddhartha Dongre